Core Insight
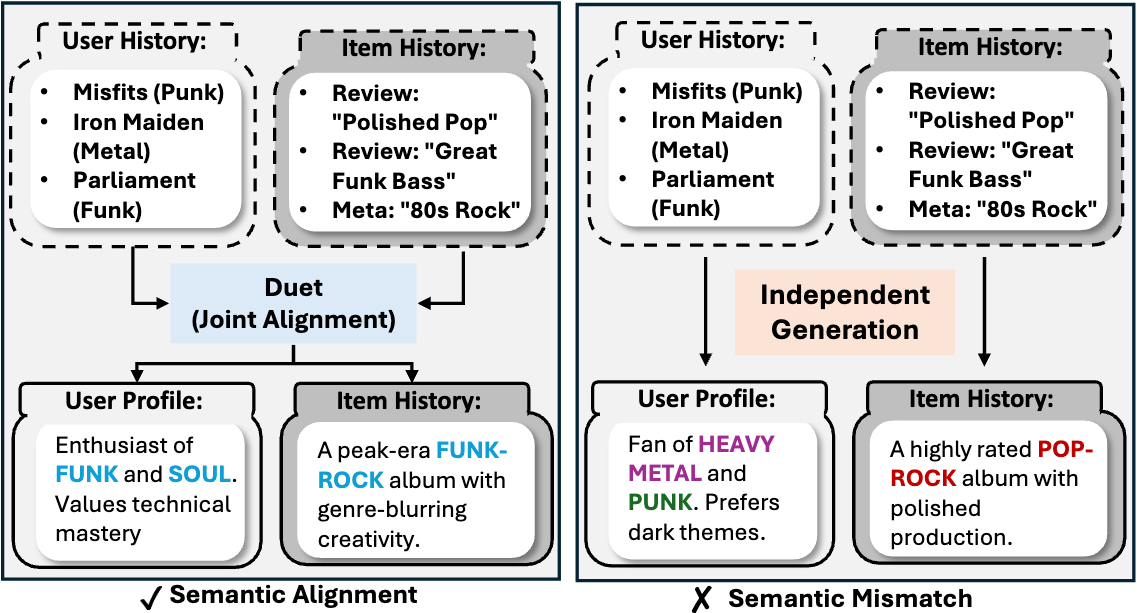
Why joint profiling matters
Independently generated profiles may amplify incompatible facets of the same user–item pair, obscuring the true relevance signal.
Independent Generation
Semantic Mismatch
User Profile
Fan of HEAVY METAL and PUNK. Prefers dark themes.
Item Profile
A highly rated POP-ROCK album with polished production.
The two profiles focus on incompatible aspects, hiding the shared funk/soul connection and producing a misleading relevance signal.
DUET — Joint Alignment
Semantic Alignment ✓
User Profile
Enthusiast of FUNK and SOUL. Values technical mastery.
Item Profile
A peak-era FUNK-ROCK album with genre-blurring creativity.
DUET reconciles both sides into a compatible interpretation, surfacing the shared funk affinity and enabling accurate relevance estimation.
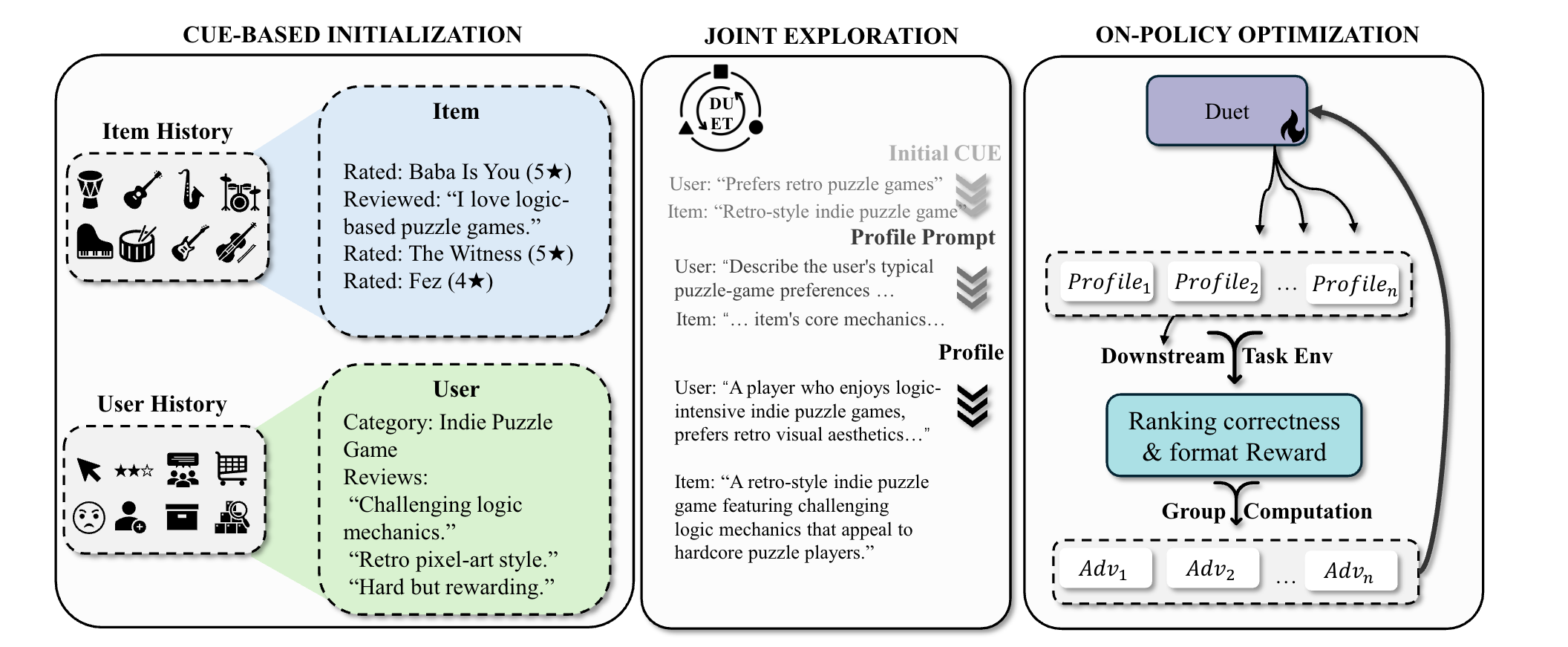
Figure 1. DUET aligns raw user and item data by transforming them into textual profiles within a shared semantic space.